

La page web que j'ai choisie à titre d'exemple sera... le blog "Électronique en Amateur" ! Nous allons faire en sorte que le Raspberry Pi Pico visite le blog et y trouve le titre de la publication la plus récente. Vous pourrez ensuite modifier ce script pour que votre Raspberry Pi Pico W affiche les conditions météorologique, les cours de la bourse, les résultats de votre équipe sportive préférée, etc.
La bibliothèque "urequests" de Micropython est spécialement conçue pour naviguer sur le web. On accède à la page web de cette façon:
page_web = urequests.get("http://electroniqueamateur.blogspot.com")
Tout le contenu html de la page est alors placé dans la chaîne de caractères (string) "page_web.text".
Il reste ensuite ensuite à extraire de cette longue chaîne de caractères les informations qui nous intéressent.
En affichant le code source de la page web, j'ai remarqué que le titre d'un article du blog est toujours précédé de ce tag html:
<h3 class='post-title entry-title' itemprop='name'>
Donc, en utilisant la méthode find pour localiser cette sous-chaîne à l'intérieure de la chaîne complète...
position = page_web.text.find("<h3 class='post-title entry-title' itemprop='name'>")
extrait = page_web.text[position:position + 300]
... j'obtiens une chaîne de 300 caractères qui contient, entre autres choses, le titre de l'article le plus récent du blog (qui s'intitule, au moment où j'écris ces lignes, "Dans un blog près de chez vous (24)"):
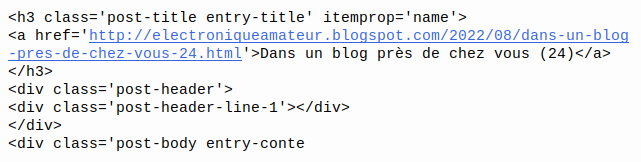
Mon extrait contient toutefois une grande quantité de caractères qui ne sont pas pertinents. On peut facilement omettre quelques dizaines de caractères au début de la chaîne. Ici, par exemple, ma chaîne débute 80 caractères plus loin:
position = page_web.text.find("<h3 class='post-title entry-title' itemprop='name'>")
extrait = page_web.text[position + 80:position + 300]
Le contenu de la variable "extrait" est maintenant:

L'url qui précède le titre de l'article n'aura pas toujours la même longueur, mais on peut détecter où il se termine en recherchant le caractère ">":
position = extrait.find(">")
extrait = extrait[position + 1:]
Le contenu de la variable "extrait" est maintenant:

position = extrait.find("<")
extrait = extrait[:position]
Maintenant, la variable "extrait" ne comporte plus que le titre désiré:

Voici le script complet:
-
-
... et le résultat affiché dans la console:

À lire également:
Aucun commentaire:
Enregistrer un commentaire